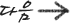랜더링 파이프라인이란? ------------------------------------------------------------------------------------
기하학 적으로 가상의 3D장면을 구성하고 가상카메라를 설정한 다음 모니터에 2D 표현을 만들어 내는 과정을 랜더링 파이프 라인이라고 한다.
랜더링 파이프라인의 단계? ------------------------------------------------------------------------------------

객체 ------------------------------------------------------------------------------------
3d에서 어떠한 물체는 x y z의 좌표를 가져야 합니다. 이걸 기본 전체로 하나 하나의 물체는 자신을 이루는 면들과.
특정 위치를 가지는 녀석을 객체라고 하겠습니다. 즉 객체란 3차원 공간 상에서 x y z의 값을 가진 녀석입니다.
정점(VERTEX) 폴리곤 ------------------------------------------------------------------------------------

정점이란 간략하게 설명해서 3D 평면상에 존재하는 하나의 점을 의미합니다.
1개의 점은 말그대로 점 2개가 있으면 직선을 만들 수 있습니다.
하지만 아직까지 3D 화면에서 보이기에는 그다지 적합하지 않은 형태입니다. 여기에 3개의 삼각형이생기게 됩니다.
세개의 정점이 만나서 생겨나는 면을 폴리곤이라고 생각해주시면 되겠습니다.
로컬 스페이스 ------------------------------------------------------------------------------------
로컬좌표란 어떠한 물체가 자신을 기준으로한 점이나 버텍스의 정보를 가진 상태로 외부 영향이 없는 상태라고 하겠습니다.
좀더 쉽게 설명하자면 무조건 0.0좌표를 기준으로 가지는 어떠한 객체를 가지고 얼마든지 그것을 늘리고 줄이고 회전시킬 수 있습니다.
즉 주변에 비교할만한 상대적 크기등이 없기 때문에 주변의 다른 객체를 고려하지 않고 모델링을 구현할수 있습니다.
현재까지는 아직 게임에 적용되지 않았다고 보면 됩니다.

월드 스페이스 ------------------------------------------------------------------------------------
하지만 모든 물체가 0.0에 존재한다면 모든 물체는 겹쳐있는 것처럼 보입니다.
일반적인 3d게임을 보면 객체와 객체 사이의 구분이 명확합니다.

사진을 보시면 말그대로 하나의 월드에 캐릭터와 나무 등이 배치되어 있는 것이 보일겁니다.
모두 x = 0, y = 0, z = 0의 위치가 아니라. 어떤 기준에 의해서 각 객체들이 각자의 좌표를 가지게 되는 것입니다.
즉 이미 어떠한 기준이 있고 그 기준에서 x y z축으로 얼마나 떨어져 있느냐를 정해준다면 그 객체는 3d 평면상에 객체가 되는 것입니다.
즉 처음의 객체는 0.0 0의 위치를 가지고 있지만 이것을 게임에 사용하기 위해서
하나의 기준 좌표를 가지고 100, 200, 100 <- 이런식으로 실제 배치될 좌표로 이동시키는 단계를 의미합니다.
이때 사용하는 함수로는 다음과 같은 함수들이 있습니다.
m_Transform.matWorld -> 어떠한 객체의 행렬
D3DXMatrixTranslation(&m_Transform.matTrans, vPos.x, vPos.y, vPos.z); -> 월드 좌표의 이곳으로 이동시킨다.
pDevice->SetTransform(D3DTS_WORLD, &m_Transform.matWorld); -> 월드좌표를 기준으로 객체의 현재 행렬을 적용시킨다.
이때 알아두셔야 할것이 SetTransform이라는 함수는 내부에 등록된 월드 좌표들을 기록해 놓는다는 것입니다.
rander() -> 객체를 그린다.
뷰 스페이스 (3D 세상은 카메라를 중심으로 돈다.) ------------------------------------------------------------------------------------
3D세상에서 각 물체가 위치하고 있다고한다면 그것을 바라보는 눈이 존재할 것입니다.
관측되지 않으면 각 위치는 의미가 없습니다.

그렇다면 관측은 어떻게 하느냐? 카메라라는 존재가 있다고 생각하고 그 카메라가 위치와 바라보는 위치를 가지고 시야가 존재한다면
그 시야에 비치는 만큼을 3d화면에서 보고 있다고 할수 있습니다.
이때 카메라가 월드의 특정 위치나 방위를 가진다면 이후 있을 투영이나 클리핑 등의 작업이 오히려 연산을 더 사용하게 됩니다.
그래서 다이렉트에서는 카메라를 다시 원점으로 돌리고, 바라보고 있던 방향을 양의 z축을 바라보게 만듭니다.
즉 원점으로 돌리고 전방을 바라보고 회전시킨다는 것이죠.
하지만 카메라만 이동하면 현재 바라보고 있던 객체들은 보이지 않게 될 것입니다.
그러므로 모든 객체들에게 카메라가 이동한 만큼의 행렬을 이동시켜 주고 카메라를 중심으로 모든 행렬을 공전 시켜 줍니다.
즉 모든 객체는 카메라의 위치와 행렬값이 원점으로 돌아온 만큼 이동후 카메라를 중심으로 공전회전을 해줘야 합니다.
D3DXMATRIX Cammatrix
D3DXVECTOR3 vectorEye -> 월드 내의 카메라 위치
D3DXVECTOR3 vectorAt -> 월드 내의 카메라가 보는 지점
D3DXVECTOR3 vectorpUp -> 월드의 업백터(0, 1, 0)
D3DXMatrixLookAtLH(&Cammatrix, &vectorEye, &vectorAt , &vectorpUp) -> 카메라가 바라보는 시점을 기준으로한 뷰 스페이스 변환 행렬을 만들어 Cammatrix에 넣어준다.
pDevice->SetTransform(D3DTS_VIEW, &Cammatrix); 카메라의 행렬을 뷰 행렬로 장치에 세팅한다.
후면 추려내기 ------------------------------------------------------------------------------------
하나의 폴리곤은 앞면과 뒷면을 가지게 됩니다. 일반적으로 뒷면은 화면에 표시되지 않는 경우가 많습니다.
물론 뒷면도 출력할수 있지만 그렇다면 상당한 낭비라고 할수 있습니다. 일반적으로 게임에서 가장 많은 자원을 소비하는 것은 랜더링작업이며.
그 작업의 부담을 줄이기 위한 방법은 역시 출력하지 않을 것은 출력하지 않는게 최고 입니다.
후면추려내기 작업은 화면에 보이지 않는 면을 출력하지 않게 하는 작업입니다.
컴퓨터는 순차적인 처리를 하는 기계라 폴리곤을 면으로 만들때도 버텍스를 하나하나 읽어들여서 하나의 면을 출력합니다.

다음과 같이 모두 같은 방향으로 정점을 변환하다 보면 면이 뒷면일 경우 읽는 순서가 반대가 될 것입니다.
이러한 면들을 후면이라고 판단하고 추려내는 작업을 하는 것을 후면추려내기라고 합니다.
후면 추려내기는 디바이스를 통해서 옵션을 설정할 수가 있습니다.
Device->SetRenderState(D3DRS_CULLMODE, D3DCULL_CCW);
D3DRS_CULLMODE- > 추려내기작업에 대한 옵션을 설정하겠다는 키 입니다.
D3DCULL_CCW -> 반시계 방향으로 그려지는 면에 대해서 랜더링을 하지 않는 옵션입니다.
D3DCULL_CW -> 시계 방향으로 그려지는 면에 대해서 랜더링을 하지 않는 옵션입니다.
D3DCULL_NONE -> 추려내기를 하지 않습니다.
조명(빛이 있으라!!!) ------------------------------------------------------------------------------------
우리가 눈으로 사물의 색과 빛 명암을 구분해낼 수 있는 것은 밫이 있기 때문입니다.
3D프로그래밍에서도 마찬가지 입니다. 각 면에 빛이 비춰져야 어떠한 색깔인지 모양을 가지고 있는지 알수가 있습니다.
조명이란 이렇게 폴리곤에 빛을 비춰서 반사되는 빛과 명암 색상을 만들어 내는 작업니다.
클리핑 ------------------------------------------------------------------------------------
앞서 후면 추려내기 작업에서 말씀했듯이 랜더링 작업은 많은 컴퓨터의 CPU나 GPU에 가장 많은 연산을 필요로 하는 작업입니다.
뷰스페이스까지 변환되었다면 화면에 보여져야할 폴리곤들이 있을 것입니다.
하지만 반대로 시야 바깥에 존재하는 보이지 않아야할 폴리곤들도 있을 것입니다.
클리핑이란 후면추려내기의 후면처럼 시야 밖에 보이지 않아야할 폴리곤들을 랜더링하지 않게 구분하는 작업을 의미합니다.
투영 ------------------------------------------------------------------------------------
클리핑 작업까지는 3D의 모든 작업이 진행되고 바라보는 카메라로 월드에서의 입체전환이 되어있는 상태를 의미합니다.
3D 세계에서 2D화면을 얻어내야 하는 작업이 남았습니다.
왜 어렵게 3D환경을 구성해 놓은걸 2D화면을 얻어내야 할까요?
모니터가 평면이기 때문입니다. 어차피 우리가 보이는 것은 모니터에 표시된 픽셀로 이루어진 2D화면을 보고 있는 것입니다. 즉 3D로 구현된 세상을
모니터로 옮기전에 2D화면으로 만드는 작업을 투영이라고 합니다. (아직 모니터에 옮긴 것은 아닙니다.)
투영작업은 투영좌표계라고 하는 특수한 좌표계로 옮겨지며 다음과 같은 좌표를 가지고 있습니다.

다음의 함수를 통해서 투영행렬을 꾸밀 수 있습니다.
D3DXMATRIX matProj 리턴받을 투영행렬을 받을 행렬의 주소값
FLOAT fFovy -> 시야각의 수직 영역 (라디안)
FLOAT fAspect -> 종횡비 = 너비 / 높이
FLOAT fNear -> 가까운 평면까지의 거리
FLOAT fFar -> 먼 평면까지의 거리
D3DXMatrixPerspectiveFovLH(&matProj, fFovy, fAspect, fNear, fFar);
뷰포트 변환 ------------------------------------------------------------------------------------
뷰포트란 투영된 각 이미지들을 모니터에 표시할수있는 크기로 다시 변환하는 작업을 의미합니다.
뷰포트를 통해서 화면의 해상도등을 정해줄수 있습니다.
또한 뷰포트 변환은 최종적으로 랜더링이 종료될때 장치에서 자동으로 처리해 줍니다.
D3DVIEWPORT9 vp;
Device->GetViewport(&vp); -> 뷰포트를 가져오고
vp.X = 100; -> 뷰포트를 다시 설정한다.
vp.Y = 100;
vp.Width = 300;
vp.Height = 300;
Device->SetViewport(&vp); -> 뷰포트를 세팅한다.
래스터라이즈 ------------------------------------------------------------------------------------
스크린 좌표로 버택스들을 변환한다음 2d삼각형들이 그려지게 되는데. 말그대로 모니터의 픽셀하나하나를 계산해서 작업하게 되므로
엄청난 연산이 필요하게 됩니다. 그래서 반드시 전용 그래픽 하드웨어를 통해서 처리 되어야 합니다.
이 래스터 라이즈의 작업까지 끝이나야 모니터 화면에 표시되는 2d이미지가 표시됩니다.