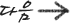1. DLL의 주요 장점
Dynamic Link Libray(DLL)에 대해 설명하기 전에,
이것이 어떠한 장점이 있고 어떠한 경우 사용하기 좋은지 살펴보도록 하자.
단순히 라이브러리화 함으로써 얻는 이점이 아닌, DLL만이 가질 수 있는 내용으로 정리하였다.
1. 애플리케이션의 기능 확장
DLL은 프로세스의 주소 공간에 동적으로 로드될 수 있기 때문에,
애플리케이션이 수행 중이더라도 수행해야 할 작업이 결정되면 해당 작업을 수행할 수 있는 코드를 로드할 수 있다.
어떤 회사가 제품을 개발하고, 다른 회사가 이 제품의 기능을
확장하거나 보강할 수 있도록 하려는 경우에도 DLL은 상당히 유용하게 사용될 수 있다.
2. 메모리 절약
두 개 혹은 그 이상의 애플리케이션이 동일한 DLL 파일을 사용할 경우, DLL을 램에 단 한 번만 로드하고,
이 DLL을 필요로 하는 애플리케이션들은 앞서 로드한 내용을 공유할 수 있다.
C/C++ 런타임 라이브러리의 경우가 대표적인 예라고 할 수 있다.
매우 많은 애플리케이션들이 CRT 라이브러리를 사용하는데,
모든 애플리케이션들이 이를 정적으로 링크하게 되면, 동일 기능들이 메모리에 여러 번 로드될 것이다.
하지만, DLL 형태의 CRT 라이브러리를 링크하게 되면, 이러한 기능들은 메모리상에
단 한번만 로드될 것이므로 메모리를 좀 더 효율적으로 사용할 수 있게 된다.
3. 지역화 촉진
Localization을 위해 DLL을 사용하곤 한다.
예를 들어, 코드로만 구성되어 있어서, 어떠한 UI 컴포넌트도 포함하고 있지 않은 형태로 구동한 뒤,
해당 지역에 맞는 DLL를 로드하여, 지역화된 UI 컴포넌트를 사용할 수 있는 것이다.
4. 플랫폼 차별성 해소
다양한 윈도우 버전들은 각기 서로 다른 함수들을 제공하고 있다.
개발자들은 운영체제가 제공하는 최신의 기능을 사용하고 싶어 하지만,
그 기능이 제공되지 않는 낮은 버전의 운영체제에서는 프로그램이 실행조차 되지 않을 수 있다.
이러한 기능을 DLL 파일로 분리해 두면, OS 버전에 맞는 DLL을 로드하여
OS가 지원하는 최대한의 신 기능을 활용하도록 환경을 구성할 수 있게 된다.
5. 특수한 목적 달성
윈도우는 단지 DLL에서만 사용 가능한 몇몇 기능들을 가지고 있다.
Hook을 설치하는 것과 같은 작업(SetWindowsHookEx, SetWinEventHook)이 그 예가 될 수 있는데,
이 때 사용하는 훅 통지 함수는 반드시 DLL 내에 존재해야 한다.
윈도우 탐색기의 shell은 DLL 파일로 작성된 COM 오브젝트를 구성함으로써 그 기능을 확장할 수 있으며,
웹 브라우저는 DLL을 이용하여 ActiveX 컨트롤을 사용, 다양한 기능을 웹 환경에 제공하고 있다.
2. DLL과 프로세스 주소 공간
DLL 파일의 이미지는 실행 파일이나 다른 DLL이 DLL 내 포함되어 있는 함수를 호출하기 전에
반드시 프로세스의 주소 공간에 매핑되어 있어야 한다.
이를 위해 다음 두 가지 방법 중 하나를 선택할 수 있다.
위 방법들에 대해선 아래 챕터에서 각각 자세히 설명하도록 하겠다.
DLL 파일 이미지가 프로세스의 주소 공간에 매핑되고 나면,
DLL이 가지고 있는 모든 함수들은 프로세스 내의 모든 쓰레드에 의해 호출될 수 있게 된다.
사실 이렇게 로드가 완료되고 나면, DLL 고유의 특성은 거의 없어진다고 볼 수 있다.
프로세스 내의 쓰레드 관점에서는 DLL이 가지고 있는 코드와 데이터들은
단순히 프로세스의 주소 공간에 로드된 추가적인 코드와 데이터들로 여겨질 뿐이다.
쓰레드가 DLL에 포함되어 있는 함수를 호출하게 되면,
호출된 DLL 함수는 호출한 쓰레드의 스택으로부터 전달된 인자 값을 얻어내고,
호출한 쓰레드의 스택을 이용하여 지역변수를 할당하게 된다.
뿐만 아니라 DLL 함수 내부에서 생성하는 모든 오브젝트들도
DLL 함수를 호출하는 쓰레드나 프로세스가 소유하게 되며, DLL 자체가 소유하는 오브젝트는 존재하지 않는다.
예를 들어, DLL 내의 특정 함수가 VirtualAlloc 함수를 호출하게 되면,
해당 함수를 호출한 쓰레드가 속해 있는 프로세스의 주소 공간 내에 영역이 예약된다.
만일 DLL이 프로세스의 주소 공간으로부터 내려간다 하더라도
앞서 프로세스의 주소 공간에 예약했던 영역은 그대로 남게 되는데,
이는 시스템이 해당 영역이 DLL로부터 예약되었다는 사실을 특별히 관리하지 않기 때문이다.
하지만, 단일의 주소 공간은 하나의 실행 모듈과 다수의 DLL 모듈로 구성되어 있음을 반드시 알아두어야 한다.
이 중 일부 모듈은 C/C++ 런타임 라이브러리를 정적으로 링크하고 있을 수도 있으며,
또 다른 모듈은 C/C++ 런타임 라이브러리를 동적으로 링크하고 있을 수도 있다.
따라서, 단일의 주소 공간 내에 C/C++ 런타임 라이브러리가 여러 번 로드될 수 있다는 사실을 잊어버리면 곤란한다.
아래 예제를 살펴보자.
-- 실행 파일의 함수 --
void EXEFunc()
{
void* pv = DLLFunc();
// pv가 가리키는 저장소를 사용한다.
// pv가 EXE의 C/C++ 런타임 힙 내에 있을 것이라고 가정한다.
free(pv);
}
-- DLL의 함수 --
void* DLLFunc()
{
// DLL의 C/C++ 런타임 힙으로부터 메모리를 할당받는다.
return (malloc(100));
}
이 코드가 정상적으로 동작할 것인가?
DLL 함수 내에서 할당받은 메모리 블럭을 EXE 함수 내에서 정상적으로 해제할 수 있는가?
위 예제는 제대로 동작할수도 있고, 그렇지 않을 수도 있다.
만일 EXE와 DLL이 모두 DLL로 구성된 C/C++ 런타임 라이브러리를 사용하고 있다면, 위 예제는 정상 동작한다.
하지만, 둘 중 하나라도 C/C++ 런타임 라이브러리를 정적으로 링크하고 있다면, free 호출 과정에서 문제가 발생할 것이다.
이러한 문제는 애초에 습관을 제대로 들이면 된다.
DLL 내 메모리를 할당하는 함수가 있다면, 해제하는 함수도 DLL에 만들고 그걸 사용하는 것이다.
-- 실행 파일의 함수 --
void EXEFunc()
{
// DLL 함수에서 할당한 메모리 블럭의 주소를 얻어온다.
void* pv = DLLAllocFunc();
// pv가 가리키는 메모리 블럭을 사용한다.
// DLL 함수를 이용해 pv를 메모리로 반환한다.
DLLFreeFunc(pv);
}
-- DLL의 할당 함수 --
void* DLLAllocFunc()
{
// DLL의 C/C++ 런타임 힙으로부터 메모리를 할당받는다.
return (malloc(100));
}
-- DLL의 해제 함수 --
void DLLFreeFunc(void* p)
{
// DLL의 C/C++ 런타임 힙에서 메모리를 해제한다.
free(p);
}
그리고, 실행 파일 내에 전역으로 선언된 정적 변수는 동일한 실행 파일이
여러 번 실행될 경우라도 Copy-on-write 메커니즘에 의해 공유되지 않는다.
DLL 파일 내에 전역으로 선언된 정적 변수 역시 이와 동일한 메커니즘이 적용된다.
프로세스가 DLL 이미지 파일을 자신의 주소 공간 내에 매핑하는 경우
실행 파일의 경우와 동일하게 전역으로 선언된 정적변수의 새로운 인스턴스가 생성된다.
3. DLL과 실행 파일 작성법
이제, DLL을 생성하는 방법과 실행 파일이 어떻게 DLL 파일의 함수나 변수를 사용해야 하는지에 대해 알아보자.
1. DLL 모듈 생성
DLL은 변수, 함수, C++ 클래스를 다른 모듈에 export 할 수 있다.
하지만, 코드의 계층적 추상화를 유지하고 DLL 코드를 좀 더 쉽게 유지/관리하기 위해
변수는 가급적 익스포트 하지 않는 것이 좋다.
또한, C++ 클래스는 export 한 C++ 클래스를 사용하는 모듈을
동일한 회사의 컴파일러를 사용하는 컴파일한 경우에만 사용할 수 있으므로 주의하도록 하자.
DLL을 작성할 때 export 하고자 하는 변수나 함수를 포함하고 있는 헤더 파일을 먼저 작성하는 것이 좋다.
이러한 헤더 파일에는 export 할 함수나 변수가 사용하는 심벌이나 데이터 구조체도 반드시 정의되어 있어야 한다.
이 헤더는 DLL과 함께 배포되어야 하며, 이 DLL을 사용하는 모듈은 이 헤더를 반드시 인클루드 해야 한다.
또한, 유지보수의 편의성을 위해 DLL 하나당 헤더 파일 1개씩 페어로 작성하는 것이 좋다.
이제 간단한 DLL 헤더의 예제를 살펴보도록 하자.
(아래 예제는 vs2010에서 DLLTest라는 DLL 프로젝트를 생성하면 기본적으로 생성시켜주는 헤더 파일이다)
#ifdef DLLTEST_EXPORTS
#define DLLTEST_API __declspec(dllexport)
#else
#define DLLTEST_API __declspec(dllimport)
#endif
// 이 변수는 DLLTest.dll에서 내보낸 것입니다.
extern DLLTEST_API int nDLLTest;
// 이 함수는 DLLTest.dll에서 내보낸 것입니다.
DLLTEST_API int fnDLLTest(void);
DLLTest 프로젝트의 전처리기에는 DLLTEST_API 가 선언되어 있다.
즉, 함수나 변수, 클래스 앞에 __declspec(dllexport) 선언 지정자가 붙는 것이다.
그리고 아래 예제는 역시 DLLTest 프로젝트가 기본 생성해준 cpp 파일이다.
// DLLTest.cpp : DLL 응용 프로그램을 위해 내보낸 함수를 정의합니다.
//
#include "stdafx.h"
#include "DLLTest.h"
// 내보낸 변수의 예제입니다.
DLLTEST_API int nDLLTest=0;
// 내보낸 함수의 예제입니다.
DLLTEST_API int fnDLLTest(void)
{
return 42;
}
위 cpp 예제에서 nDLLTest 변수와 fnDLLTest 함수 앞에 DLLTEST_API 매크로가 붙어 있지만,
cpp에서는 DLLTEST_API를 붙이지 않아도 무방하다.
자, 이제 위와 같이 기본 생성된 DLL 프로젝트를 빌드하고, DLL을 생성해 보자.
Output 폴더에 가보면, 다음 두 개의 파일이 생성되어 있다.
DLL 파일을 컴파일하면, 컴파일이 끝난 후 링커는 DLL의 소스코드가
적어도 하나 이상의 함수/변수를 export 하고 있는지를 확인하고, 그 경우 .lib 파일을 생성한다.
.lib 파일은 어떠한 함수나 변수도 포함하고 있지 않기 때문에 그 크기가 매우 작으며,
단순히 DLL 파일이 export 하고 있는 함수나 변수의 심벌 이름만을 유지하고 있다.
이 파일은 DLL 파일이 export 하는 심볼을 참조하는 실행 모듈을 링크하는 과정에서 반드시 필요하다.
(이 내용은 DLL을 암시적 로드타임 링크할 때만 유효하다)
.lib 파일을 생성하는 것 외에도 링커는 DLL 파일 내에 해당 파일이
export 하고 있는 심볼에 대한 정보를 테이블 형태로 포함시켜 준다.
export section이라고 불리는 이 테이블은 export 하고 있는
변수, 함수, 클래스 심볼에 대한 목록을 (알파벳순으로) 가지고 있다.
링커는 이 외에도 상대 가상 주소(RVA:Relative Virtual Address)를 DLL 파일 내에 포함시키는데,
이 값은 각각의 심볼들이 DLL 모듈 내의 어느 위치에 있는지를 가리키는 값이다.
그럼 이제 DLLTest에서 export 하고자 한 변수와 함수가 제대로 export 되어 있는지를 dumpbin으로 확인해 보자.
꾸엑~
함수명 fnDLLTest은 ?fnDLLTest@@YAHZX로
변수명 nDLLTest은 ?nDLLTest@@3HA로 naming 되어 있다.
이것은 C++ 컴파일러가 C++ 특성(override나 등등의)을 위해 컴파일시 함수나 변수명에 name mangling을 하기 때문이다.
물론 DLL도 C++로 작성하고, 사용 모듈 역시 C++로 작성된다면 실행에 아무런 방해가 되지 않는다.
하지만, DLL은 C++로 작성하고, 사용 모듈이 C로 작성될 수도 있는 상황이라면,
C로 작성한 사용 모듈에서 DLL 함수를 호출하면 링크 과정에서 존재하지 않는 심볼 참조 에러가 발생하게 된다.
이를 해결하기 위해선, extern "C" 를 사용하는 방법이 있다.
즉, 위 헤더를 다음과 같이 변경하는 것이다.
#ifdef DLLTEST_EXPORTS
#define DLLTEST_API extern "C" __declspec(dllexport)
#else
#define DLLTEST_API extern "C" __declspec(dllimport)
#endif
// 이 변수는 DLLTest.dll에서 내보낸 것입니다.
DLLTEST_API int nDLLTest;
// 이 함수는 DLLTest.dll에서 내보낸 것입니다.
DLLTEST_API int fnDLLTest(void);
하지만, extern "C" 는 C++ 클래스 사용시엔 문제가 발생하므로, 클래스는 조심해서 한정자를 사용해야 한다.
자 이제, 다시 한번 DLL 프로젝트를 빌드하고, dumpbin으로 확인해 보자.
오~ 깨끗하게 나온다.
헌데, 이 상태에서 fnDLLTest 함수의 calling convention을 __stdcall로 바꾸고 싶어졌다.
문제는 M$ C 컴파일러가 __stdcall 함수에 대해선 C++를 사용하지 않다 하더라도,
함수의 이름을 멋대로 바꾸는 작업을 수행한다는 것이다.
함수의 이름 앞에 _ (underbar)를 붙이고, 함수의 이름 뒤엔 매개변수 크기의 총합을 @와 함께 표시한다.
위 예제의 fnDLLTest 함수를 __stdcall로 호출하면, dumpbin 결과가 아래와 같이 나온다.
역시 fnDLLTest 함수명이 바뀌었기에,
DLL을 사용하는 모듈이 타사의 컴파일러를 사용하는 경우 링크 에러를 발생시키게 된다.
다른 회사의 컴파일러에서 사용될 DLL 파일을 M$ 컴파일러를 사용해 컴파일하려 하면,
컴파일러에게 이름 변환을 수행하지 않도록 확실한 명령을 주어야만 한다.
두 가지 방법이 있으나, 두 번째 방법은 별로이므로, 한가지만 소개하겠다.
바로 .def 파일을 프로젝트에 추가하고 EXPORTS 섹션을 구성하는 것이다.
.def 파일은 DLL의 ouput name과 동일하게 맞추어야 한다.
LIBRARY DLLTest
EXPORTS
fnDLLTest
nDLLTest
M$ 링커는 .def 파일을 분석하는 과정에서 fnDLLTest와 _fnDLLTest@0 이라는 두 개의 함수가 export 되었음을 인지하게 된다.
그러나 이 두 함수의 이름이 서로 일치하기 때문에 (이름 변환 과정을 배제할 경우)
.def 파일에 정의되어 있는 fnDLLTest 라는 함수만 export 하고, _fnDLLTest@0 는 export 하지 않는다.
사실 .def 방식이 가장 확실하다.
.def 파일을 사용하면,
- extern "C"를 붙이든 그렇지 않든,
- 함수의 calling convention으로 __stdcall을 사용하든
naming에 있어 아무런 문제가 되지 않는다.
만약, 자신이 만든 DLL이 널리 배포될 용도로 제작되어야 한다면,
조금 귀찮더라도 .def 파일을 프로젝트에 추가하고, EXPORTS 섹션을 구성함을 가장 추천한다.
물론, M$ 컴파일러로 DLL을 만들고, 사용 모듈 역시 M$ 컴파일러로 만들고, 둘의 환경 모두 C++이라면
아무 것도 하지 않아도 문제가 되진 않는다.
2. 실행 모듈 생성
우선, 아래 내용은 DLL을 Implicit Loadtime Link 할 경우에 초점이 맞추어져 있다.
실행 파일의 소스 코드를 개발할 때에는 반드시 DLL과 함께 제공되는 헤더 파일을 인클루드해 주어야 한다.
실행 파일의 소스 코드에서는 DLL 헤더 파일을 인클루드할 때, DLLTEST_EXPORTS 를 정의해선 안 된다.
정의하지 않은 채 코드를 컴파일하게 되면,
DLLTest.h 파일 내에서 DLLTEST_EXPORTS를 __declspec(dllimport)로 정의하게 된다.
// DLL 헤더 인클루드
#include "DLLTest.h"
// 테스트를 위한 암시적 로드타임 링킹
#pragma comment(lib, "DLLTest.lib")
int _tmain(int argc, _TCHAR* argv[])
{
// DLL의 변수에 값 설정
nDLLTest = 1;
// DLL의 함수 호출
int num = fnDLLTest();
return 0;
}
컴파일러가 변수, 함수, C++ 클래스에 대해 __declspec(dllimport) 한정자를 발견하게 되면,
이러한 심볼들이 다른 DLL 모듈에서 임포트된 것임을 알게 된다.
다음 단계로 링커는 실행 파일의 소스 코드에서 사용되고 있는 심볼들이 어떤 DLL로부터 export 된 것인지를 확인해야 한다.
이를 위해 링커에게 .lib 파일을 전달해 주어야 한다.
앞서 말한 것과 같이 .lib 파일은 단순히 DLL 모듈이 export 하고 있는 심볼들에 대한 목록만을 가지고 있다.
링커는 import 된 심볼을 찾는 과정에서 import section이라는 특수한 섹션을 실행 파일 내에 추가한다.
이 import section은 실행 파일이 필요로 하는 DLL 모듈과 해당 DLL 모듈에서 참조되는 심볼에 대한 목록이 포함되어 있다.
이제 실행 파일을 생성하고, dumpbin으로 내용을 확인해 보자.
DLLTester.exe의 import 섹션에서 DLLTest.dll의 fnDLLTest 함수와 nDLLTest 변수의 심볼을 확인할 수 있다.
이제 실행 파일을 실행해 보자.
실행 파일이 실행되면...
- 운영체제의 로더는 프로세스를 위한 가상 주소 공간을 생성한다.
- 이후, 로더는 실행 모듈을 프로세스의 주소 공간에 매핑한다.
- 로더는 실행 파일의 import section을 확인하여 필요한 DLL 파일들을 찾아서 프로세스의 주소 공간에 추가 매핑한다.
Import section 내에 포함된 DLL 이름은 전체 경로명을 포함하고 있지 않기 때문에,
로더는 사용자의 디스크 드라이브로부터 DLL을 검색해야 한다.
아래에 로더의 검색 순서를 나타내었다.
- 실행 파일 이미지가 있는 디렉토리
- GetSystemDirectory 함수의 반환 값인 윈도우 시스템 디렉토리 (Windows\System32)
- 16비트 시스템 디렉토리 (Windows\System)
- GetWindowsDirectory 함수의 반환 값인 윈도우 디렉토리 (Windows\)
- 프로세스의 현재 디렉토리
- PATH 환경 변수에 포함된 디렉토리
DLL 모듈이 프로세스의 주소 공간에 매핑되면, 로더는 각 DLL 파일의 import section을 조사한다.
(DLL 역시 다른 DLL을 링크할 수 있기 때문에...)
만일 import section이 존재한다면, 로더는 계속해서 프로세스의 주소 공간에
추가적으로 필요한 DLL 파일들을 매핑시켜 나단다.
로더는 DLL 모듈을 지속적으로 추적하여, 설사 여라 차례 참조되는 모듈이라 하더라도,
단 한번만 로드되고 매핑될 수 있도록 한다.
모든 DLL 모듈들이 프로세스의 주소 공간에 로드되고 매핑되면,
로더는 import 된 심볼의 모든 참조 정보를 수정해 나간다.
이를 위해 각 모듈의 import section을 다시 한번 살펴보게 된다.
로더는 각각의 심볼에 대해 관련 DLL의 export section을 검토하고 심볼이 실제로 존재하는지 확인한다.
로더는 심볼의 RVA 정보를 가져와서 DLL 모듈이 로드되어 있는 가상 주소 공간에 그 값을 더한다.
이후, 실행 모듈의 import section 내에 계산된 가상 주소 값을 기록한다.
이제 코드에서 import 된 심볼을 참조하게 되면 호출 모듈의 import section으로부터
import 된 심볼의 위치 정보를 가져와서 import 된 변수, 함수, C++ 클래스의 멤버 함수에 성공적으로 접근할 수 있게 된다.
애플리케이션이 새로 실행될 때마다 위와 같은 과정을 거쳐야 하므로, 초기 구동에 많은 비용을 소비하게 된다.
애플리케이션의 로딩 속도를 향상시키기 위해 실행 파일과 DLL 모듈에 대해
시작 위치 변경(rebase)과 바인딩(binding) 작업을 수행하는 것이 좋다.
Rebase와 binding에 대해서는 추후 별도로 글을 하나 더 쓰는 것이 좋을 듯 하다.
4. Implicit Loadtime Link
암시적 로드타임 링크는 static libaray를 링크하는 방법과 완전히 동일한 방법으로 수행할 수 있다.
또한, static library를 링크하는 것처럼 DLL의 export된 모든 변수와 함수, C++ 클래스가
프로세스의 주소 공간에 매핑된다.
암시적 로드타임 링크시 어떻게 프로세스 주소 공간에 매핑되고,
프로세스에서 DLL 내 심볼에 접근하는지에 대한 과정은 위 3-2. 실행 모듈 작성 챕터에 자세히 설명되어 있다.
암시적 로드타임 링크는 역시 편안함에 기인한다.
프로세스의 주 쓰레드가 돌기 시작한 이후
별도로 DLL을 로드/해제할 필요가 없고, 심볼 역시 별도의 시작 주소를 얻어오는 과정 없이 바로 사용할 수 있기 때문이다.
Static library와 링크하는 방법이 똑같지만, 이왕 정리하는 김에
암시적 로드타임 링크를 하는 두 가지 방법에 대해 다시 한번 소개하겠다.
1. 프로젝트 속성의 링커-입력에 .lib 추가
프로젝트 속성 - 링커 - 입력에 DLL의 .lib 파일을 추가하는 것이다.
2. comment 지시어 사용
위 3-2 예제에 나왔듯이 comment 지시어를 사용하여, 암시적 로드타임 링크를 시킬 수 있다.
// 암시적 로드타임 링킹
#pragma comment(lib, "DLLTest.lib")
개인적으로는 2번 방법을 선호하는 편이다.
위에서도 썼듯이, 프로젝트 속성에서 제어하는 방법은
공동 작업자가 꼼꼼히 속성을 살피지 않으면 지나치기 일수라,
코드에서 명백하게 링크하는 것이 경험상 훨씬 더 직관적인 것 같다.
5. Explicit Runtime Link
암시적 로드타임 링크가 프로세스가 시작되는 과정에서
암묵적으로 로더가 DLL을 프로세스의 주소 공간에 로드/매핑 시켜주는 것이라면,
명시적 런타임 링크는 애플리케이션이 수행 중인 상황에서 필요한 심볼을 명시적으로 링크하는 방법을 말한다.
다르게 표현하면, 애플리케이션이 수행되고 있는 상황에서
특정 쓰레드가 DLL 내에 포함되어 있는 함수를 호출하기로 결정한 경우
프로세스의 주소 공간에 필요한 DLL 파일을 명시적으로 로드하여
DLL 내에 포함되어 있는 함수의 가상 메모리 주소를 획득한 후, 이 값을 이용하여 함수를 호출하는 것을 말한다.
이 방식의 매력은 모든 과정들이 애플리케이션이 수행 중인 상황에서 이루어진다는 것이다.
또한, 암시적 로드타임 링크는 프로세스 시작 과정에서 DLL 로드/매핑까지 함께 이루어지기에,
많은 수의 DLL을 링크할 경우 프로세스 구동 자체가 오래 걸릴 수 있는 문제가 있으나.
명시적 런타임 링크의 경우 이 비용을 분산시킬 수 있다.
그리고, DLL 사용 후 더 이상 필요치 않을 경우
가상 메모리에서 해제시킬수도 있기에 메모리도 효율적으로 관리할 수 있다.
또한, 암시적 로드타임 링크와 다르게 명시적 런타임 링크시에는 .lib 파일에 사용되지 않는다.
이제 명시적 런타임 링크를 사용하는 방법에 대해 본격적으로 설명하겠다.
명시적 런타임 링크에 사용되는 세 가지 함수는 아래와 같다.
- LoadLibrary
- GetProcAddress
- FreeLibrary
1. LoadLibrary
프로세스 내의 쓰레드는 LoadLibrary 함수를 통해 프로세스의 주소 공간에 DLL을 런타임에 매핑할 수 있다.
HMODULE LoadLibrary(PCTSTR pszDLLPathName);
// 또는...
HMODULE LoadLibraryEx(
PCTSTR pszDLLPathName,
HANDLE hFile, // reserved. 반드시 NULL을 넘겨야 한다.
DWORD flags); // 0을 넘기거나 다양한 flag를 OR해서 넘기면 된다.
이 함수들은 사용자의 시스템에서 파일 이미지를 검색하고 (검색 순서는 3-2. 로더의 검색 순서와 동일하다)
함수를 호출한 프로세스의 주소 공간에 DLL 파일 이미지를 매핑하려고 시도한다.
함수 호출이 성공하면, 파일 이미지가 매핑된 가상 메모리 주소를 나타내는 HMODULE 값을 반환한다.
(HMODULE은 HINSTANCE와 완전히 동일한 의미이며, 혼용 또한 가능하다)
함수 호출이 실패하면? NULL을 반환한다.
LoadLibraryEx는 flags 변수를 통해 다양한 옵션을 줄 수 있다.
자세한 설명은 생략한다 ㅋ 가 아니라,
MSDN 페이지에서 확인하기 바란다.
다만, 이 둘을 혼용하는 것은 원하지 않은 결과를 초래할 수 있으므로, 추천하지 않는다.
디스크 상에 동일한 DLL을 이용하여 로드하였다 하여도,
LoadLibrary와 LoadLibraryEx 함수가 반환하는 매핑 주소 값은 LoadLibraryEx의 flag에 따라 달라질 수 있다.
LoadLibrary(Ex) 함수를 사용하게 되면, 프로세스별로 DLL에 대한 usage count를 증가시킨다.
예를 들어, DLL을 로드하기 위해 LoadLibrary 함수를 최초로 수행한 경우
시스템은 DLL 파일 이미지를 프로세스의 주소 공간에 매핑하고, DLL의 usage count를 1로 설정한다.
만일 동일 프로세스 내의 쓰레드가 동일한 DLL 파일 이미지에 대해 LoadLibrary를 또다시 호출하게 되면,
시스템은 DLL 파일 이미지를 프로세스의 주소 공간에 두 번 매핑하지 않고, DLL의 usage count만 2로 증가시킨다.
이후 설명할 FreeLibrary를 호출하면, 해당 프로세스의 usage count가 감소되며,
usage count가 0 이 되면, 시스템은 프로세스의 주소 공간으로부터 DLL 파일 이미지를 매핑 해제한다.
위에서도 썼지만, 시스템은 DLL의 usage count를 프로세스별로 유지한다.
A 프로세스에서와 B 프로세스가 XXX.dll을 로드하게 되면,
A 프로세스 / B 프로세스 모두 XXX.dll의 usage count는 1로 설정된다.
이후 B 프로세스가 FreeLibrary를 호출하여, usage count를 0으로 감소시키면,
B 프로세스의 주소 공간으로부터 DLL 파일 이미지를 매핑 해제시키겠지만
A 프로세스는 여전히 usage count가 1이며, 프로세스 주소 공간에 DLL이 매핑되어 있다.
2. GetProcAddress
쓰레드가 DLL 모듈을 명시적으로 로드하였다면,
이제 GetProcAddress를 통해 export 된 심볼에 대한 시작 주소를 얻어와야 한다.
FARPROC GetProcAddress(HMODULE hInstDll, PCSTR pszSymbolName);
첫번째 인자인 hInstDll은 LoadLibrary(Ex) 반환 값을 넘겨주면 된다.
두번째 인자인 pszSymbolName이 ANSI 문자열임에 주목하라.
이는 컴파일러/링커가 심볼의 이름을 DLL의 export section에 기록할 때, 항상 ANSI 문자열로 기록하기 때문이다.
두번째 인자로 문자열 대신 숫자를 넘기는 방법도 있으나,
이 방법은 M$가 deprecate 시킬 것이니 그만 사용할 것을 강조하고 있으니, 패스하겠다.
GetProcAddress로 함수 심볼을 얻어오려 할 때엔,
GetProcAddress로 얻은 주소를 적절한 원형의 함수 포인터로 형변환을 해 주어야 한다.
즉, DLL 내의 함수가 다음과 같은 원형이라면
bool GetParrity(int type);
다음과 같이 함수 포인터 타입을 만들어 놓고,
typedef bool (*pfnGetParrity)(int);
GetProcAddress의 반환값을 함수 포인터 타입으로 형변환을 해 주어야 하는 것이다.
pfnGetParrity fnGetParrity = (pfnGetParrity)GetProcAddress(hInstDll, "fnGetParrity");
bool result = fnGetParrity(1);
3. FreeLibrary
프로세스 내의 쓰레드에서 더 이상 DLL 파일 내의 심볼을 사용할 필요가 없게 되면,
FreeLibrary 함수를 호출하여 프로세스의 주소 공간으로부터 DLL 파일을 명시적으로 unload 할 수 있다.
BOOL FreeLibrary(HMODULE hInstDll);
이 함수의 인자인 hInstDll은 LoadLibrary(Ex)의 반환값을 넘겨주면 된다.
위 LoadLibrary 설명에서도 썼듯이, FreeLibrary는 프로세스의 DLL usage count를 감소시킨다.
usage count가 0 이 되면, 시스템은 프로세스의 주소 공간으로부터 DLL 파일 이미지를 매핑 해제한다.
4. 정리 예제
마지막으로 지금까지 알아본 LoadLibrary, GetProcAddress, FreeLibrary 함수들을 사용하는 간단한 예제를 첨부하겠다.
#include <Windows.h>
// DLL 헤더 인클루드
#include "DLLTest.h"
// fnDLL 함수 포인터 타입데푸
typedef int (*pfnDLLTest)(void);
int _tmain(int argc, _TCHAR* argv[])
{
///////////////////////////////////////////////////////////////////
// DLLTest.dll을 명시적으로 로드한다.
// 프로세스의 DLL usage count 증가
HMODULE hModule = LoadLibrary(_T("DLLTest.dll"));
if (nullptr == hModule)
{
return -1;
}
///////////////////////////////////////////////////////////////////
// DLL의 변수 심볼의 주소 얻어오기
// GetProcAddress의 두번째 인자는 ANSI 스트링만 넘길 수 있다.
// 이는 export section에 심볼 이름이 ANSI 스트링으로 저장되기 때문이다.
int* pDllNum = (int*)GetProcAddress(hModule, "nDLLTest");
if (nullptr == pDllNum)
{
return -1;
}
// DLL 변수 참조
int numInDLL = *pDllNum;
///////////////////////////////////////////////////////////////////
// DLL의 함수 심볼의 주소 얻어오기
pfnDLLTest pfnDLLTestFunc = (pfnDLLTest)GetProcAddress(hModule, "fnDLLTest");
if (nullptr == pfnDLLTestFunc)
{
return -1;
}
// DLL 함수 호출
int dllFuncNum = pfnDLLTestFunc();
///////////////////////////////////////////////////////////////////
// DLLTest.dll을 명시적으로 해제한다
// 프로세스의 DLL usage count 감소
// DLL의 reference count가 0이면, 해당 프로세스의 주소 공간에서 영역 해제
FreeLibrary(hModule);
return 0;
}