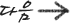프로세스를 이해해보자 ---------------------------------------------------------------------------------------------------------
여러분이 게임을 즐기기위해서 어떤 실행파일과 그에 관련된 제반 파일들을 프로그램이라고 한다.
이제 실행을 위해서 실행파일을 더블클릭한 순간 프로그램의 실행을 위해서 메인메모리(RAM)에 할당이 이루어지 이고 이 메모리 공간에 바이너리 코드가 올라가면서 프로그램은 프로세스라고 불리게 된다.
즉 프로세스랑 실행중에 있는 프로그램을 의미한다.
프로세스가 되면 메인메모리에 프로세스를 위한 메모리 공간이 할당되며 메모리 공간의 구조는 다음과 같다.

프로세스의 메모리 구성 ---------------------------------------------------------------------------------------
CODE 영역 : 실행파일을 구성하는 명령어들이 올라가는 영역
DATA 영역 : 전역변수나 STATIC 변수의 할당을 위해서 존재하는 영역
HEAP 영역 : 동적할당을 위해서 존재하는 힙영역
STATK 영역 : 지역변수 할당과 함수호출시 전달되는 인자값들의 저장을 위해서 존재하는 영역
이중 STATK 영역은 점점 위로 차오르고(함수호출이 많아지게 되면) HEAP 영역은 (동적할당이 많아질수록)아래로 증가하게 된다.
프로세스와 CPU레지스트 --------------------------------------------------------------------------------------
프로그램 실행을 위해서는 레지스터들이 절대적으로 필요하며, 어떤 프로그램을 실행하면 CPU의 레지스터들은 현재 실행중인 프로그램을 위한 데이터들로 채워진다. 그러므로 레지스터의 상태또한 프로세스의 일부로 포함시켜서 말할수가 있다.
프로세스의 스케줄링과 상태변화---------------------------------------------------------------------------------
윈도우프로그램을 생각해보면 동시에 여러개의 프로그램이 실행되기도 합니다. 게임을 하면서 음성채팅을 할수도 있고 메신저를 동시에 켤 수도 있는 이유는 무엇일까?
이유는 간단하다. CPU가 여러개의 프로그램을 사용자가 느낄 수 없을 정도로 고속으로 번갈아가며 실행시킨다. CPU란 기본적으로 순차적으로 진행된다. 그러므로 여러개의 프로세스가 실행중이라고 해서 세개의 프로세스가 CPU를 동시에 차지하고 실행되는 것은 아니다.
그렇게 되면 A B C의 세가지 프로세스가 실행중이라고 할때 어떤 순서로 어떻게 실행될까를 결정해야 한다.
이렇게 프로세스의 CPU할당 순서 및 방법을 결정짓는 것을 스케줄링(Scheduling)이라고 한다.
그리고 이때 사용하는 알고리즘을 스케줄링 알고리즘(Scheduling Algorithms) 이라고 한다.
이러한 스케줄링은 소프트웨어적으로 동시에 프로세스를 실행할 수 있는 운영체제마다 구현되어 있다.
프로세스의 상태 ----------------------------------------------------------------------------------------------
프로세스에서 하는 가장 큰 일중 하나는 I/0(입력 및 출력)이다. 자신에게 할당된 메모리에 입력과 출력을 하는 동안 CPU가 쉴수는 없으므로 스케줄러를 통해서 다른 프로세스가 실행되도록 한다. 즉 CPU가 잠시도 쉬지않게 하기 위해서 지속적으로 프로세스의 실행순서를 조정해야 한다.
이를 가능하게 하는 것은 프로세스의 상태를 주는 것이다.
이 상태를 구분짓자면 Start, Ready, Running, Blocked, Exit의 세가지 상태가 있다.
A B C라는 프로세스가 있을때 각 프로세스는 Start와 동시에 Ready상태에 들어간다. Ready상태는 스케줄러에게 실행되기는 요청하고 있는 상태라고 보면 된다. 그리고 Ready상태는 스케줄러에게 관리되고 있다는 것을 의미하기도 한다.
스케줄러는 각 Ready상태의 프로세스중 하나를 선택하여 Running상태로 변경한다. 이 Running상태가 되어야 프로세스가 실행되고 있다고 볼 수 있다.
하지만 하나의 프로세스가 Running이라는 것은 다른 프로세스들은 Ready상태라는 것을 의미하고 각 프로세스가 스케줄링 알고리즘에 의해서 언젠가는 Running상태가 되어야 한다는 것을 의미한다. 그리고 각 프로세스마다 그에 대한 순서가 필요하다. 순서가 없다면 프로세스들이 뒤죽박죽으로 실행될 것이기 때문이다.
이러한 현재 Ready상태의 프로세스들의 Running이 되어야할 순서를 우선순위(Priority)라고 한다.
마지막으로 Blocked상태는 이름처럼 프로세스가 실행을 멈추는 상태다. 일반적으로 데이터 입출력에 관련된 일을 하는 경우에 발생한다.
이렇게 한 프로그램이 Blocked상태에 들어가면 이 시간중에는 CPU가 쉬게 할수 없으므로 현재 Ready인 녀석중 한녀석을 선택해서 Running상태로 변경해 줘야 한다.
그리고 이런 Blocked상태에서 종료를 하게 되면 Exit 즉 프로세서가 소멸된 상태가 된다

그림으로 보자면 이와 같다.
컨텍스트 스위칭 ----------------------------------------------------------------------------------------------
-- 프로세스와 CPU레지스트 항목중에서 --
프로그램 실행을 위해서는 레지스터들이 절대적으로 필요하며, 어떤 프로그램을 실행하면 CPU의 레지스터들은 현재 실행중인 프로그램을 위한 데이터들로 채워진다.
라는 구분이 기억나는가? 당연히 CPU는 현재 프로세스되는 녀석들의 데이터를 가지고 있어야 한다. Ready상태인 프로세스는 언젠가는 Running상태가 되어야 하고 당연히 이때 CPU는 Running상태의 프로세스의 데이터들로 채워져야 한다.

그를 위해서 이와 같이 메모리에 있는 프로세스의 데이터를 교체하는 것을 컨텍스트 스위칭이라고 한다.
하지만 이렇게 헤지스터의 데이터를 통채로 교체하는 작업은 당연히 CPU에 큰 부담을 주므로 프로그래머라면 자신이 개발하는 프로그램의 성격에 따라서 이를 고려하여 프로그래밍 해야 한다.
'게임개발공부 > 서적공부' 카테고리의 다른 글
| 윈도우 시스템 프로그래밍 <커널오브젝트> (0) | 2013.11.16 |
|---|---|
| 윈도우 시스템 프로그래밍 <프로세스의 생성> (0) | 2013.11.16 |
| 시스템프로그래밍 <명령어> (0) | 2013.11.13 |
| 시스템 프로그래밍 64비트 기반 프로그래밍 (0) | 2013.11.12 |
| 시스템프로그래밍 아스키, 유니코드 (0) | 2013.11.12 |