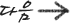SQL소개
STRUCTURED QUERY LANGUAGE의 머리글자를 딴 말이며 SQL그대로 읽는다. 아주 가끔 SEQUEL(씨퀄)이라고 잘못 읽는 사람이 있는데, 씨퀄은 옛날 이름이다. 에스 큐 엘로 읽으면 된다. SQL의 뜻은 “구조화된 질의어”이다. SQL에 구조화는 크게 중요하지 않은데도, SQL 이름에는 그대로 남아있다.
현재 SQL은 관계형 데이터베이스의 질의어로는 제1의 자리를 굳혀서 아마 관계형 데이터베이스를 쓸경우 90%이상 SQL을 쓰게 될것이다. 앞에서 관계대수에 대해서 배웠는데 실제 데이터베이스 시스템은 관계 대수 연산만으로는 자료를 처리하지 못한다. 관계 대수 연산은 자료를 고치는 명령(INSERT/DELETE/UPDATE)은 없이, 그냥 들어있는 자료를 가져오기만 하는 질의어(QUERY LANGUAGE)이고, 또한 스키마를 정의하는 명령은 존재하지 않는다.
SQL은 그런 모자라는 부분을 보안하여 실제 데이터베이스에서 사용이 가능하게 만들어진 언어이다.
SQL은 말 그대로 데이터베이스의 표준어 같은 느낌이지만 개발되는 프로그램에 따라서 SQL을 일부만 지원하거나 혹은 거대한 데이터베이스 관리 프로그램이라면 오히려 그 이상의 확장된 기능까지 지원하는 경우도 있다.
국제표준 SQL
SQL은 1970년대에 처음 구현되기 시작하여 그 뒤 많은 변화가 있었다. 현재 SQL은 국제 표준화 기구(ISO: International Organization for Standardization)에서 표준을 만든다고 한다.
당연히 표준이 만들어 질 때마다 버전처럼 번호를 정하는데 국내 기준은 KS X 2017이라고 한다.
SQL에 들어가 있는 기본 기능들을 살펴보자면.
1 스키마를 정의하는 자료 정의어 (DDL: data definition language)
2 질의어 또는 자료 조작어 (DML: data manipulation language)
그런데 여기에서 질의어는 2가지 종류로 나뉘게 된다.
2-1. 상호 작용적(interactive) 자료 조작어 : 화변에서 명령을 넣고, 결과가 바로 화면으로 나오는 방식인데 이 방식은 거의 늘 지원된다. 보기를 들어, Oracle 경우에는 이를 SQL*Plus 라고 부른다. 학생들이 실습하기에 좋은 환경이다.
2-2. 내포된 (embedded) 자료 조작어 : 일반 고급 프로그래밍 언어(보기: C/C++, PL/I, Cobol, Pascal)로 싼 프로그램 안에 SQL 명령을 사이 사이 에 끼워 넣은 방식. 작은 데이터베이스 관리 시스댐에서는 이를 지원하지 않는다. 은행 업무, 철도/비행기 예약 업무등과 같이 늘 되풀이되는 실제의 업무 전산화에서는 이런 방식을 아주 많이 쓴다
3. 트레젝션 제어(transaction control)
4. 이외 뷰 정의, 무결성 제어, 권한 주기 등
자료의 형(domain, type)
Select, insert, delete, update등은 데이터 베이스의 자료를 다루는 DML명령들이다. 그런데 이러한 자료를 테이블에 담으려면 테이블의 속성에 대한 자료의 형 (domain = 범위)를 포함하여 스키마를 정의하는 DDL을 먼저 배워야 된다.
자료형이란 고급 프로그래밍 언어에서 사용하는 int char double같은 타입과 비슷하다. SQL을 사용하면서도 이를 모르면 안되는 것이다.
그럼 많이 사용하는 자료형에 대해서 알아보자.
Char(n) : fixed – length character string으로 저장하며, 이때 n은 기억 장소의 크기를 의미한다. 필요한 때에는 마지만에 빈칸을 (‘’, 0x20)을 덧붙인다. 보기를 보자면 char(3)에 ab를 저장하면 ‘ab’가 메모리에 저장되는게 아니라 ‘ab ‘가 저장되는 것이다. 실제 char 배열에서도 최종에 null을 넣어주는 것과 동일하다.
Varchar2(n) = variable – length character string 으로 저장하며, 이때 n은 최대 길이지만, 그보다 짧은 문자열이 들어오면 마지막에 빈칸을 덧붙이지 않고 짧은 문자열 그대로 저장한다. 오라클의 경우 Varchar Varchar2가 동일하게 작동하지만 Varchar2를 사용할 것을 권장한다.
Int, smallint : int는 보통 정수이고 smallint는 int보다 바이트수가 적은 정수형이다.
Numeric(p, d), number(p, d), decimal(p, d), dec(p, d) 십진 수를 정확하게 저장할 수 있는 자료형이다. P는 전체 자리수, d는 그 가운데 소수점 아래의 자리수를 의미한다. 보기를 들어 Numeric(3, 2)라고 한다면 1.23 식으로 정수 1개 소수점 2자리를 표시할 수 있다.
Real, double, float(p) : 실수형이다. Real은 보통의 실수이고 double는 real보다 바이트수가 많은 실수형이다. Float(n) n자리까지 실수를 저장한다.
실수 형 보충설명
컴퓨터 안에서 실수는 IEEE 754 표준에 따라서 보통 2진법으로 저장하는데 십진법으로 정확하게 나타낼 수 있는 값이 2진법으로는 나타낼 수 없는 경우가 있다. 10진법으로 0.1은 2진법으로는 정확하게 나타낼 수 없다. 물론 오차가 아주 작아서 상관없는 경우가 있지만 만약 정확하게 나타내야 한다면 Numeric같은 형을 사용해야 한다.
DATE : 날짜를 나타내는 자료형
TIME : 시간을 나타내는 자료형
여기에 자료형또한 데이터베이스 시스템마다 새롭게 정의할 수 있으니 그때 그때 맞춰서 잘 사용해야 한다.
CREATE TABLE 명령을 사용하여 스키마 정의하기
스키마를 정의하는 명령은 create table 이고, 스키마를 지우는 명령은 drop table이다.
create table 테이블-이름 (
속성_이름1 자료-형1, 속성 _이름2 자료-형2, . … ,
primary key (속성 11 , 속성 12 , ... ),
unique key (속성 21 , 속성 22 , ... ),
foreÎgn key (속성 31 , 속성 32 , ... ) references 테이블_이름2
);
drop table 테이블-이름 ;
여기에서 주의할 점은 primary key(일차 키)절이 나오면 그 키 값이 꼭 같은 투플은 그 테이블 안에 두개 이상 있을 수 없다. 일차 키는 하나 또는 여러 개의 속성으로 이루어지는데, 만약 유저 항목에 아이디가 일차 키라면 그 테이블 안의 모든 투플들은 아이디가 달라야 한다.
또한 어떤 테이블에 unique key(유일한 키)절이 나오면 그 키 값이 꼭 같은 투플이 그 테이블 안에 두개 이상 있을 수 없다. 어떤 테이블에서 후보키가 2개 있을 때 일차키가 되지 못한 키를 unique key로 지정하면 된다.
속성에 대한 자료형을 지정한 뒤 그 뒤에 ‘not null’이라고 지정할 수 있는 not null이라면 그 속성에 대한 값으로 null을 허용하지 않는다는 말이다.
** 여기서 주의할 점은 어떤 테이블의 primary key에 속하는 모든 속성은 not null로 선언하지 않아도 null값은 허용하지 않는다. 그 밖의 경우에는 not null로 선언하지 않는다면 null값을 사용할 수 있으며 unique key와 foreign key의 일부로 지정된 속성의 값도(생각해보면 알겠지만 당연히 바람직하지 않다.)
create table 학생
(학번 char(7) not null ,
이름 char(20) not null ,
주번 char(14) not null ,
primary key (학번),
unique key (주번)
);
여기에서 (학번 char(7), 으로만 선언해도 primary key (학번), 라고 선언했으므로 학번은 자동으로 not null이다.
다음은 foreign Key(외래키) 가 들어간 내용을 살펴보자.
create table 수강
(확번 char(7) not null,
과목번호 char(7) not null ,
primary key (학번, 과목번호) ,
foreign key (학번) references 학생,
foreign key (과목번호) references 과목
);
foreign key 라고 선언된 것은 다른 스키마에서 키로 사용되고 있는 외래키라는 선언이며 references는 가져온 스키마의 명칭을 적는다.
테이블에 투플 넣기
create table 유저
(아이디 char(7) not null ,
패스워드 char(20) not null ,
);
ínsert ínto 유저 values (’전사전사’, ‘1258’);
insert 명령의 values 절에 속성 값을 넣게 되는데 테이블을 만들 때의 속성 순서대로 값을 넣을 때는 위와 같이 사용하지만 순서와 상관없이 하는 건 후에 배우겠다.
테이블 복사하기
이미 있는 테이블과 스키마도 똑같고 투플의 내용도 같은 테이블을 만드는 방법을 알아보자. 참고로 이 문법은 oracle에서 사용한 것이며 다른 DBMS에서는 지원하지 않을 수도 있다.
Create table copytable as select * from 유저; (기존 테이블을 복사해서 몇가지 기능을 실험해보고 싶을 때 유용할 것이다.)
여기에 추가로 조건을 줘서 사용하고 싶다면
Create table copytable as select 아이디 from 유저 where 패스워드 = ‘11111111’
식으로 사용할 수 있겠다.
Select – from – where 실행원리
엄밀한 뜻에서 자료를 가져오는 명령은 select이다. Select 명령에는 여러가지 절이 들어 갈수 있지만 가장 중요한 절은 from절과 where절이며 select 명령 형식은 다음과 같다.
Select 속성1, 속성2, …
From 테이블1, 테이블2, …
Where 조건1, AND/OR 조건2 …
SELECT 명령에서 From 절은 반드시 있어야 한다. Where 절은 보통 있지만 반드시 있어야 하는 것은 아니다.
명령의 단계별로 본다면 다음과 같이 해석할 수 있다.
|
유저 |
||
|
아이디 |
패스워드 |
캐릭터 |
|
법사법사 |
1234568 |
전사 |
|
법사법사 |
1234568 |
도적 |
|
전사전사 |
856412 |
마법사 |
|
전사전사 |
856412 |
전사 |
|
도둑도둑 |
987523 |
궁수 |
다음과 같은 테이블이 있다고 쳤을시.
Select 아이디
Form 유저
|
아이디 |
|
법사법사 |
|
법사법사 |
|
전사전사 |
|
전사전사 |
|
도둑도둑 |
다음과 같은 결과가 나오게 된다. 이것이
Select 아이디, 패스워드, 캐릭터
Form 유저라면
|
아이디 |
패스워드 |
캐릭터 |
|
법사법사 |
1234568 |
전사 |
|
법사법사 |
1234568 |
도적 |
|
전사전사 |
856412 |
마법사 |
|
전사전사 |
856412 |
전사 |
|
도둑도둑 |
987523 |
궁수 |
와 같을 것이다. 여기에
Select 아이디, 패스워드, 캐릭터
Form 유저
Where 아이디 = 법사법사
라면
|
아이디 |
패스워드 |
캐릭터 |
|
법사법사 |
1234568 |
전사 |
|
법사법사 |
1234568 |
도적 |
다음과 같을 것이다.
관계대수 연산으로 보자면
Π 아이디, 패스워드, 캐릭터 (σ 아이디 = 법사법사 (유저) );
결론적으로 위의 select의 기본형은 다음과 같다.
Π 속성1 , 속성2 , ... (σ 조건 1 and/or, 조건 2, … (테이블1 X 테이블2 ...) )
가 된다.
여기에서 테이블1 x 테이블2 라는 내용을 보자면
유저 이외에 Temp라는 테이블도 넣는경우
Select 아이디, 패스워드, 캐릭터
Form 유저, Temp
Where 아이디 = 법사법사
Π 아이디, 패스워드, 캐릭터 (σ 아이디 = 법사법사 (유저xTemp) );
라는 구문으로 해석할 수 있다는 뜻이 된다.
이제 단계별로 요약해보자.
1. From 절에는, 이 select 명령에서 쓰고자 하는 테이블 이름이 나오는데, 테이블(엄밀하게 말하면 투플 변수 이름)이 둘 이상 있을 때 “개념적으로” 모든 테이블(투플변수가 가리키는 테이블)의 카티전 곱을 한 결과 테이블을 다음 단계로 넘긴다. 만일 from 절에도 테이블 이름이 하나만 나오면 카티전 곱을 하지 않고 그냥 테이블을 넘긴다(할 수도 없다.).
2. where 절에는 조건이 나오는데, 관계대수(σ)의 선택연산을 한다. 조건이 여러 개 있으면, 원하는 바에 따라 and or을 붙이면 된다. Where 절은 반드시 있어야 하는 것은 아니지만 , 실제로는 거의 모든 select 명령에는 where절이 있다.
3. select명령 바로 뒤에 나오는 “속성1, 속성2, … ”은 관계대수의 속성추출(Π) 연산을 하며 최종적으로 나온 테이블에서 필요한 속성만 빼내는 것이 명령의 최종 결과이다.
하지만 이에 대한 DBMS의 구현은 각기 다르며 실제 카티전 곱을 실행하는 경우 등은 없다. 이유는 실제 만들어진 DBMS마다 연산 최적화를 거칠 수 도 있으며 결과적으로 나오는 테이블이 중요할 것이지 내부연산의 결과는 크게 중요하지 않을 수 있다.
Select로 속성 추출
결국 select명령이란 데이터를 뽑아오는 것이다. 그리고 현재까지는 들어온 예로는 결과적으로 최종 테이블에는 겹치는 투플이 존재하지 않았다.
하지만 select명령의 결과에 겹치는 결과가 나오지 않거나 데이터테이블에 완벽히 겹치지 않는 투플만 존재하게 할 수 있을까?
그럴 수는 없다. 이유는 생각해보면 간단하다 결국 select나 insert update명령을 생각해보면 한번한번의 연산 추출한번할 때마다 한투플 한투플이 겹치는지 겹치지 않는지 연산해야 할 것이다. 이는 성능에 심각한 저하를 줄 수 있다.
그래서 나온 타협안이 다음과 같다.
1. Insert/update 명령의 결과로 표안에 겹치는 투플이 생기는 것은 허용한다.
2. select 명령의 경우
Select (또는 select all)의 경우 결과 테이블에 겹치는 투플을 허용한다.
Select distinct의 경우 결과 테이블에 겹치는 투플을 허용하지 않는다.
즉 select 명령을 실행할 때
Select : 겹치는 투플 허용
Select all : 겹치는 투플 허용
Select distinct : 겹치는 투플 허용하지 않음
등으로 이는 선택한 속성의 수가 몇 개가 되든 문제 없다.
Where로 조건 나타내기
Where로 저건을 나타내는 것은 일반 조건문과 비슷하다.
Where 유저 = ㅋㅋㅋ
Where 공격력 > 2000
자연조인 나타내기
관계대수에서 자연조인을 where문으로 나타낼 수 있다. SQL에서 자연조인을 어떻게 나타내는지 보자.
유저 = (아이디, 패스워드)
캐릭터 = (아이디, 공격력, 방어력, 직업)
자연조인 단계를 생각하면서 확인해보자.
1. 학생과 수강 테이블의 카티전 곱 = FROM 유저, 캐릭터
2. 유저 아이디와 캐릭터 아이디가 같은 투플 선택 = where 유저.아이디 = 캐릭터.아이디
3. 두 테이블에서 공통 속성은 한번만 출력 = select 유저.아이디, 유저.패스워드, 캐릭터.공격력, 캐릭터.방어력, 캐릭터.직업
묶어서 보자.
Select 유저.아이디, 유저.패스워드, 캐릭터.공격력, 캐릭터.방어력, 캐릭터.직업
From 유저, 캐릭터
where 유저.아이디 = 캐릭터.아이디
select 다음에 속성을 다음과 같이 나타내도 꼭 같다.
select, 유저.* 캐릭터.공격력, 캐릭터.방어력, 캐릭터.직업
from 유저, 캐릭터
where 유저.아이디 = 캐릭터.아이디 ;
** 이때 캐릭터.공격력, 캐릭터.방어력, 캐릭터.직업 과 같은 구문은 다른 테이블과 겹치지 않으므로 캐릭터라는 항목을 빼도 되겠지만 어떤 데이터베이스 시스템이냐에 따라서 다를 수 있다.
속성의 이름을 정하거나 바꾸거나(renaming attributes [as])
속성에 이름이 없을 때 새 이름을 주거나 이미 이름이 있는데 다른 이름을 붙이려면 as를 쓰고 새 이름을 적어야 한다.
그럼 어떤 경우에 쓸까?
1. 다른 테이블 2개에 같은 이름의 속성이 하나씩 있을 때.
유저.아이디, 캐릭터.아이디 같은 경우가 다음과 같다. MMORPG같은 경우 캐릭터는 누가 소유하고 있는지 분명히 해야 하는데 같은 이름의 아이디라는 항목이 2개 있으면 분명 햇갈릴 수가 있다.
이런 경우 다음과 같이 as문을 이용할 수 있다.
Select 유저.아이디 as 유저_아이디, 캐릭터.아이디 as 보유유저아이디
From 유저, 캐릭터
where 유저.아이디 = 캐릭터.아이디
2. select 다음에 속성대신 수식이 올 때.
캐릭터 = (보유아이디, 공격력, 방어력)
Select 보유아이디, 공격력 * 10
From 캐릭터;
이럴 때 공격력 * 10이라고 하면 내용을 찍기는 하겠지만 이름이 없을 것이므로
Select 보유아이디, 공격력 * 10 as 밸런스조정공격력
From 캐릭터;
등으로 표현할 수가 있다.
이 내용들은 후에 배울 집계(aggregate)항목에서 같이 적용된다.
3. 이미 있는 속성이름과 다른 속성이름을 주려고 할 때.
Select 공격력
From 캐릭터;
현재 시간당 공격력의 의미로도 쓰이기 때문에 Dps이라는 이름을 주고 싶으면
Select 공격력 as Dps
From 캐릭터;
식으로 주면 된다.
테이블을 가리키는 투플변수
이제까지 테이블과 투플변수의 관계에 대해서 살펴보지 못했는데 이 기회에 알아보도록 하자.
Select 유저.아이디 as 유저_아이디, 캐릭터.아이디 as 보유유저아이디
From 유저, 캐릭터
where 유저.아이디 = 캐릭터.아이디
와 같은 경우를 봤을 때 유지.아이디가 당연하게 느껴질 수도 있다. 하지만 실제로 저런 식으로 사용하는 건 앞장에서 투플변수에 대해서 설명할 때 사용했던 문법이다. 우리는 투플 변수를 선언한적도 없는데 어떻게 저런 문법이 가능할까?
이에 대한 설명으로는 마치 C++의 디폴트 생성자처럼 어디선가 우리가 선언도 하지 않았는데 무시적으로 투플변수를 만들어 낸다. 그리고 묵시적으로 만들어내는 투플변수는 테이블 명과 동일하게 만들어진다. 라는 생각을 해볼 수 있다.
Select 유저.아이디 as 유저_아이디, 캐릭터.아이디 as 보유유저아이디
From 유저, 캐릭터
where 유저.아이디 = 캐릭터.아이디
우리가 실제로 본 이 위와 같은 명령중 From에서는 무시적으로 다음과 같이 처리하고 있다.
Select 유저.아이디 as 유저_아이디, 캐릭터.아이디 as 보유유저아이디
From 유저(테이블명) 유저(투플변수), 캐릭터(테이블명) 캐릭터(투플변수)
where 유저.아이디 = 캐릭터.아이디
즉 다음과 같이 바꾼다면 select에서도 변경해줘야 한다는 것.
Select Var유저.아이디, Var캐릭터.아이디 as 보유유저아이디
From 유저 Var유저, 캐릭터 Var캐릭터
where 유저.아이디 = 캐릭터.아이디
또한 as 명령은 사실 있어도 되고 없어도 된다. 위의 명령은 아래의 명령과 동일하게 작동한다.
Select Var유저.아이디, Var캐릭터.아이디 as 보유유저아이디
From 유저 as Var유저, 캐릭터 as Var캐릭터
where 유저.아이디 = 캐릭터.아이디
어떤 DBMS시스템은 as명령을 지원 안하기도 한다. 오라클이 대표적이다.
같은 테이블에 대하여 둘이상의 투플변수를 정의하는 경우.
|
캐릭터 |
||
|
아이디 |
공격력 |
방어력 |
|
법사법사 |
10 |
10 |
|
마수마수 |
20 |
20 |
|
전사전사 |
30 |
30 |
|
궁수궁수 |
40 |
40 |
|
도둑도둑 |
50 |
50 |
여태껏 from명령에서는 일반적으로 2개의 테이블을 사용했다. 그런데 하나의 테이블에서 어떤 유저와 어떤 유저를 비교하려면 어떻게 해야 할까? 답은 의외로 간단하다. 하나의 테이블에 2개의 투플변수를 선언하여 하면 된다.
Select T2캐릭터.아이디, T2캐릭터.공격력
From 캐릭터 T1캐릭터, 캐릭터 T2캐릭터
여기에 자신 내부에서 특정 투플들을 뽑아내기 위한 좀더 복잡한 조건들을 사용해보자.
Select T1캐릭터.아이디, T1캐릭터.공격력
From 캐릭터 T1캐릭터, 캐릭터 T2캐릭터, 캐릭터 T3캐릭터
Where T2캐릭터.아이디 = 마수마수 and T3캐릭터.아이디 = 궁수궁수 and T1캐릭터.공격력 < T2캐릭터.공격력 and T1캐릭터.공격력 > T3캐릭터.공격력
이런식으로 사용한다면
|
전사전사 |
30 |
30 |
투풀만이 뽑혀져 나올 것이다.
이를 좀더 생각해보면 테이블이 몇 개이든 상관없이 연산이 가능할 것이다.
문자열(character string) 연산
문자열의 패턴을 다루는 특별한 연산이 존재한다. like연산으로 like연산은 where 절 안에서 속성이 어떤 패턴에 맞는지를 확인할 수 있다. 먼저 보기를 하나 살펴보자.
Select 아이디
From 유저
Where 이름 like ‘% 전사%’
여기에서 %기호는 글자가 0개, 1개, 2개 등에 해당한다. % 전사%는 글자앞에 글자가 전혀 없어도 좋고, 어떤 한글자가 있어도 좋다는 이야기이다.
다음 문자열들은 % 전사%와 비교했을 때 참이다.
“ 전사” “조 전사” “박 전사”
“ 전사1” “ 전사2” “ 전사 0”
Like 다음 _(underscore)글자가 올 수도 있는데, 이 글자는 어떤 글자이든 딱 한 글자에만 해당한다.
Where 이름 like ‘__전사%’ 이런 조건이라면
참 = “ 전사” “미친전사” “호호전사”
거짓 = “ 전사” “완미친전사” “호호호호전사”
두글자면 앞에 허용하는데 3글자가 앞에 오거나 4글자가 오면 당연히 안된다. 말 그대로 글자수를 딱 지키게 하기 위한 조건이다.
일반적으로 고급 프로그래밍 언어에서 “ ”는 한바이트에 해당하지만 NLS_LANG 환경 변수를 KOREAN_KOREA.K016KSC5601로 설정하면 밑줄은 한 글자마디 하나에 해당한다. 즉 ‘a’와 한글 ‘에’는 같게 본다.
마찬가지로 ‘ ’공백과 ‘공’도 같은 글자 수로 치게 된다.
투플 간추리기 (order by)
앞에서 보았듯 select 명령의 결과테이블에서 나오는 투플은 데이터베이스 관리 시스템에서 정한 순서대로 나온다. 즉 자신이 원하는 순서 혹은 자신이 원하는 정렬대로 테이블이 출력되도록 하는 명령이라고 보면 된다.
Select 아이디
From 유저
Order by 아이디
와 같이 사용하면 아이디가 가나다 순으로 정렬되어 나오게 된다. 기본적으로 아무런 명령도 내리지 않은 order by 아이디는 올림차순으로 정렬되게 된다.
당연히 그 반대로 있다.
Select 아이디
From 유저
Order by 아이디 asc <- 올림차순 정렬
Order by 아이디 desc <- 내림차순 정렬
만약 두가지 속성을 정렬해서 보려고 한다면 어떻게 하면 될까?
Select 아이디, 패스워드
From 유저
Order by 아이디, 패스워드;
식으로 정렬하면 된다. 혹은 맨 마지막 구문을 다음과 같이 적어도 같은 결과를 낸다.
Order by 아이디 asc, 패스워드 asc;
만약 아이디는 올림으로 하지만 그 안에서 패스워드는 내림차순으로 하고 싶다면 다음과 같이 명령할 수 있다.
Order by 아이디 asc, 패스워드 desc;
이때 정렬 원칙은 첫번째 속성을 기준으로 간추리고 그 다음 속성으로 정렬 그 다음 속성으로 정렬하는 방식이다.
'게임개발공부 > 서적공부' 카테고리의 다른 글
| 알기쉽게 해설한 데이터 베이스론 3장 1) (1) | 2014.08.09 |
|---|---|
| 알기쉽게 해설한 데이터 베이스론 2장 1) (2) | 2014.08.08 |
| 알기쉽게 해설한 데이터 베이스론 1장 3) (1) | 2014.07.31 |
| 알기쉽게 해설한 데이터 베이스론 1장 2) (2) | 2014.07.30 |
| 알기쉽게 해설한 데이터 베이스론 1장 1) (0) | 2014.07.30 |