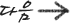자료 정의어(DDL: data definition language)
자료 정의어는 스키마를 정의하는 언어이다. 스키마 정보는 자료 사전(data dictionary, 또는 자료 목록(= data directory)이라고도 함)에 들어 있다. 스키마 정보란, 자료(보기: 아이디, 패스워드 등)에 대한 자료(보기: 아이디의 자료형은 char이고 몇자리의 char인지)인데, 이를 메타데이터(metadata)라고 보통 부른다.
SQL에서 자료 정의어의 보기를 들면 다음과 같다.
create table 유저 {순서 인덱스 char(7), 아이디 char(10), 패스워드 char(15), 보유 캐릭터 개수 int };
자료 조작어(DML: data manipulation language)
자료 조작어는, 데이터베이스 안에 있는 자료를 가져오거나(retrieve), 없에거나(delete) 바꾸거나(update), 데이터 베이스에 새 자료를 넣는(insert)일을 한다.
SQL에서 자료 조작어의 보기를 들면 다음과 같다.
select *
from 유저
where 아이디 = ’홍길동’;
insert into 유저
values ('9902101' ’ 흥길동’);
delete
from 유저
where 아이디 = 홍길동’?
update 유저
set 아이디 = '장길산’
where 아이디 = 홍길동’ ;
자료 조작어의 성질 : 비절차적, 집합 결과
자료 조작어의 성질을 말할때 책에 따라서 풀이가 좀 달라서 혼란스러운데 다음과 같이 두가지 독립적인 기준에 나눌수 있으며, 그 결과 2*2의 네가지 로 나눌 수 있다.
첫째 절차적인지 (procedural) 비절차적인지 (non - procedural)
우리가 많이 쓰는 c 등의 고급프로그래밍 언어는 거의 모두 절차적이다.
int a = 0; 이런 문장은 정수형 a를 선언하여 메모리 상에 올리고 거기에 0을 대입하는 절차적인 과정을 거친다.
절차적인 자료 조작어로는, 뒤에서 배우게 될 관계 대수 (relational algebra), 그리고 계층적 모델과 네트웍 모델에서 쓰는 자료 조작어가 있다.
비절차적 언어로는 관계 해석(relational calculus)가 있으며, 또한 관계 해석을 많이 채택한 SQL에서도 비절차적 면을 볼수 있다.(SQL은 관계 해석과 관계 대수 두가지에 바탕을 두고 있다.)
비절차적 언어의 특징을 살펴보면, 보기를 들어 유저, 아이디, 캐릭터라는 속성으로 이루어진 유저라는 테이블이 있을때 유저 테이블의 스키마와 인스턴스가 아래와 같다면
유저 순서인덱스 아이디 캐릭터
0000000001 ID1 전사
0000000002 ID2 전사
0000000003 ID1 마법사
0000000004 ID2 마법사
이테이블에서 캐릭터가 마법사인 유저의 아이디를 찾아내라고 한다면 절차적 언어에서는 FOR문등으로 반복을 돌면서 찾게 될 것이다.
그에 비해서 비절차적 언어인 SQL을 쓴다면 어떤 철자적인 내용에 대해서는 말하지 않고 다음과 같이 쓸것이다.
select 순서인덱스
form 유저
where 캐릭터 = "마법사"
둘째, 자료 조작어의 명령 결과로 한번에 레코드가 한개(recored-at-a-time)씩 나오는지 아니면 여러개의 자료(자료의 집합)가 한꺼번에 나오는지 (set-at-a-time)에 따라서 두가지로 나뉜다. 조합해 보면 다음과 같다.
비절차적 한개씩 (이녀석은 별로 없다고 한다)
비절차적 자료집합 (관계 해석 SQL)
절차적 한개씩 (계층적 모델, 네트웍모델)
절차적 자료집합 (관계 대수)
질의어(query language)와 자료 조작어(DML)
질의어(쿼리)라는 낱말은 원래 뜻은 물어보다이며 데이터 베이스와 관련하여서는 이미 있는 자료나 정보를 가져오는 것이다. SQL에서 보면 select만 해당되고 insert, delete, update는 해당되지 않는다.
이에 비해, 자료 조작어(DML)는 이미 있는 자료를 가져오는 것뿐만 아니라, 있는 자료를 지우거나 고치는 것과, 새 자료를 넣는 것까지 할수 있으므로 질의어 보다 더 넓은 개념이다. SQL에서 보면 select, insert,delete, update를 모두 포함하는 개념이다.
그렇지만, 오늘날 실제로 질의어라는 용어를 원래의 뜻대로 있는 자료를 가져오는 것에 국한하여 쓰는 일은 아주 드물다. 거의 모든 사람들은 쿼리문을 자료 조작어와 맞바꾸어 쓸수 있는, 뜻이 같은 용어로 본다. 낱말의 원래 뜻을 생각하면 잘못된 용법이지만, 오늘날 거의 모든 사람들이 이렇게 하므로 그냥 관습을 따를 수 밖에 없다고 본다.
데이터 베이스 관리자(DBA: Database Administrator)
데이터 베이스 관리자는 데이터베이스 관리 시스템을 관리할 뿐만 아니라, 데이터베이스, 그리고 그 기관에서 개별된 응용 프로그램을 관리한다. 작은 기관의 경우에는 한사람이 관리자 일을 할 수도 있을 것이고, 큰 기관에서는 관리자의 일을 여러 사람이 맡게 된다.
관리자는 그 밖에도 자료 접근 권한을 정하고 바꾸는 일, 무결성 제약 조건을 정하는 일을 한다.
데이터 베이스 사용자
데이터 베이스 사용자의 종류는 너무 많고, 또한 나누는 기준에 따라 다르지면 몇가지 종류를 보자면
응용프로그래머 : 주어진 데이터베이스 관리시스템을 써서 그 기관에 필요한 응용프로그램을 만든다. 게임을 만드는 프로그래머도 이에 속한다. 이 경우 보통의 SQL(이른 바 상호 작용적 SQL: interactive SQL)을 바로 쓰기보다는 주로 내포된(embedded) SQL을 많이 사용한다.
일반사용자 : 만들어진 응용프로그램을 쓰는 사람인데, 실제로 이런사람이 엄청 많다. 뭐 그냥 실생활에 쓰이는 대부분을 보면 된다. 우리 자신들 이니까.
4GL 운영체제
4GL(fourth generation language)
4GL 데이터베이스를 다루기 위하여 쓰는 언어 가운데 4GL이라는 것이 있다.
제 1세대 언어는 1GL(first-generation language)라고 하며 기계어(machine langage)가 여기에 속한다.
제 2세대 언어는 어셈블리 언어
우리가 쓰는 c같은 고급언어를 3세대 언어라고 한다.
4GL이란 3GL보다 한단계 더 높다고 보다는데, 일반적으로 데이터베이스 환경에서 양식을 만들거나 화면에 자료를 보여주는 프로그램을 쉽게 짤 수 있게 해주는 것이 4GL의 주요 기능이다. 그런데 SQL은 표준화가 잘되어있어서, SQL 프로그램이 다른 데이터베이스 관리 시스템에 옮겨가더라도 별 어려움 없이 잘 돌아간다. 하지만 4GL은 표준화가 전혀 되어 있지 않아서, 다른 데이터 베이스 관리 시스템에 옮겨가서 쓸 수가 없다는 단점이 있다.
데이터 베이스 관리 자체(DBMS) 와 운영 체제(OS)
운영 체제의 관점에서 보면 데이터베이스 관리 시스템은 어디까지나 하나의 응용프로그램이므로, 데이터베이스 관리 시스템은 운영체제 위에서 돌아간다. 위에서 돌아간다고 해서 데이터베이스 관리시스템이 운영체제를 관리한다는 것은 아니다. 운영체제가 데이터베이스 관리 시스템을 통체한다.
일반적으로 파일을 처리하는 응용프로그램의 경우, 응용 프로그램에서 운영체제의 파일관리자를 통하여 파일을 처리하게 된다. 그런데 데이터베이스 응용프로그램은 파일의 내용을 바꾸려면, 먼저 데이터베이스 관리시스템에 이를 요청하고, 데이터베이스 시스템은 다시 운영체제의 파일 관리자를 통하여 파일을 처리하게 된다.
'게임개발공부 > 서적공부' 카테고리의 다른 글
| 알기쉽게 해설한 데이터 베이스론 3장 1) (1) | 2014.08.09 |
|---|---|
| 알기쉽게 해설한 데이터 베이스론 2장 1) (2) | 2014.08.08 |
| 알기쉽게 해설한 데이터 베이스론 1장 2) (2) | 2014.07.30 |
| 알기쉽게 해설한 데이터 베이스론 1장 1) (0) | 2014.07.30 |
| 윈도우 시스템 프로그래밍 <비동기 I/O APC> (0) | 2013.11.26 |